Python to bardzo poręczne narzędzie o szerokim zastosowaniu i gdzie nie przyłożyć ucho, tam słychać w branży, jak dużą, ten język, robi karierę przy innowacyjnych projektach związanych ze sztuczną inteligencją, uczeniem maszynowym lub Big Data.

Python jest często używany do przetwarzania danych, ponieważ posiada bogate biblioteki i narzędzia, które ułatwiają manipulowanie danymi oraz ich analizowanie. Oto kilka sposobów, jak można wykorzystać Pythona do przetwarzania danych:
- Importowanie i eksportowanie danych: Python umożliwia łatwe importowanie danych z różnych źródeł, takich jak pliki XML, CSV, Excela lub bazy danych, a następnie eksportowanie ich do innego formatu, np. takiego jak plik CSV lub SQL.
- Manipulacja danych: Python posiada wiele narzędzi do manipulacji danych, takich jak Pandas, które umożliwiają wybieranie, filtrowanie i agregowanie danych, a także dodawanie lub usuwanie kolumn lub wierszy.
- Wizualizacja danych: Python ma również szerokie możliwości wizualizacji danych, dzięki bibliotekom takim jak Matplotlib i Seaborn, które pozwalają na tworzenie różnego rodzaju wykresów i diagramów, takich jak wykresy liniowe, słupkowe i kołowe.
- Analiza danych: Python posiada również narzędzia do analizy danych, takie jak SciPy i scikit-learn, które umożliwiają wykonywanie różnych operacji matematycznych i statystycznych, a także uczenie maszynowe i sztuczną inteligencję.
Ogólnie rzecz biorąc, Python jest potężnym narzędziem do przetwarzania danych, dzięki swoim bogatym bibliotekom i narzędziom, które umożliwiają importowanie, manipulowanie, wizualizowanie i analizowanie danych. Jego prosta składnia i elastyczność sprawiają, że jest atrakcyjnym wyborem dla programistów pracujących z danymi.
Do czego używamy Pythona w LSB DATA?
W naszym przypadku Python znalazł zastosowanie przy obróbce danych i pełni funkcję kombajnu, który zbierze, przetworzy i wyprodukuje dane w pożądanym formacie.
Wielu z naszych klientów działających w handlu boryka się z problemami gromadzenia i przetwarzania danych od wielu różnych dostawców swoich produktów.
Każdy dystrybutor to kolejne źródło danych udostępniane na różnych zasadach i w różnych formatach.
Przykład
Wyobraźmy sobie sytuację w której internetowy sklep z żarówkami staje przed wyzwaniem zgromadzenia danych ofertowych pięciu różnych dystrybutorów różnego rodzaju żarówek.
Zadanie jest jeszcze znośne gdy wszyscy klienci wysyłają dane w jednym ustalonym formacie pliku CSV a zawartość oferty w miarę trzyma ustalone parametry, takie jak Nazwa / Opis / Kod EAN / Cena / Dostępna ilość / Minimalna ilość zamówienia / Cena przy zamówieniu większej ilości / Itd.
Niestety rzeczywistość nie jest tak piękna i często pozycja małego lub średniego sklepu nie jest w stanie w takiej relacji wynegocjować sztywnych kryteriów otrzymywanej oferty dla ułatwienia procesu importu, a przy takiej ilości dystrybutorów możemy dostać pakiety danych w różnych formatach CSV / XLS / XML lub różnymi kanałami: FTP / HTTP / EMAIL.
Poniżej ilustracja prezentująca relację sklep i pięciu różnych dystrybutorów.
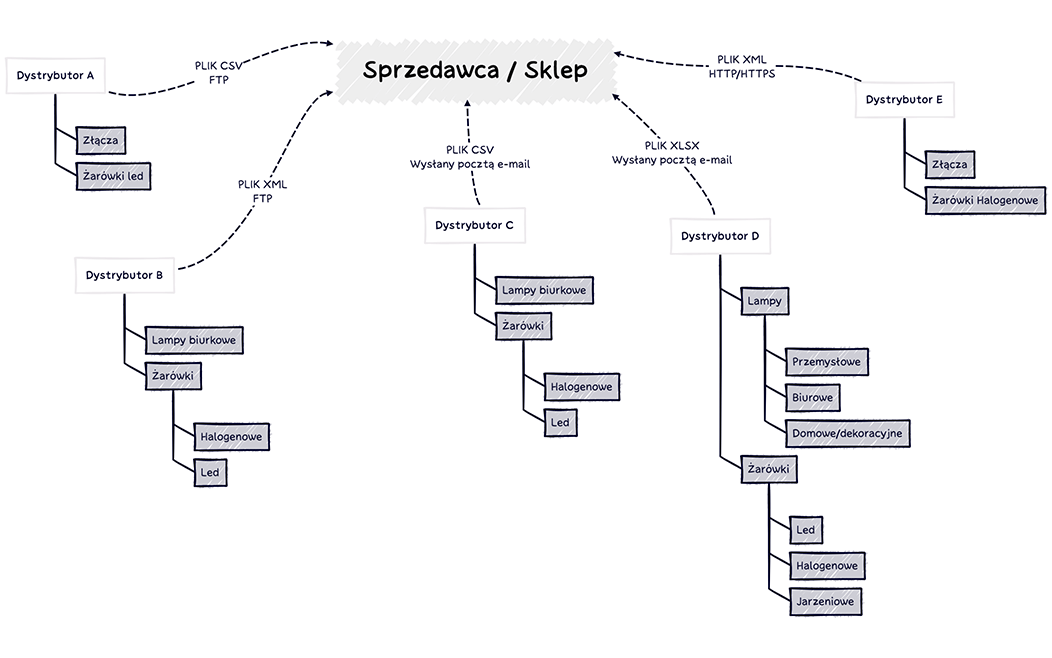
Taki scenariusz będzie generować wiele roboczogodzin, które można zaoszczędzić używając wszechstronności języka Python.
Aby skrypt Pythona mógł te wszystkie dane sprowadzić do wspólnego formatu/mianownika zrozumiałego dla mechanizmu importującego dane do naszego sklepu będziemy potrzebowali serwera, na którym będzie zainstalowany Python + kilka bibliotek Pythona oraz przygotowaną skrzynkę email, z której skrypt Pythona będzie mógł odebrać dane z plikami.
Co sprawia, że Python tak dobrze sprawdza się w zadaniach polegających na przetwarzaniu danych? Pierwszym argumentem popierającym to stwierdzenie jest jego wydajność. Można się sprzeczać, że dzisiejsze komputery są super wydajne i się nie męczą, więc dlaczego mielibyśmy się przejmować wydajnością tego czy innego rozwiązania? Dla przykładu plik o rozmiarze większym niż 200 MB - 300 MB nie jest niczym nadzwyczajnym, ale gdy naszym zadaniem będzie analiza i przetworzenie 10 - 20 takich plików to zaczynają pojawiać się problemy z wydajnością i płynnością wymiany danych, a to może prowadzić do bardziej widocznych objawów, na przykład w opóźnieniach w aktualizacji stanów magazynowych, co nie będzie już bez znaczenia dla naszego biznesu. Dlatego tak ważne jest stosowanie wydajnych rozwiązań.

Potrzebujesz dedykowanej aplikacji?
Wydajność i prostota
Dla zaprezentowania różnicy porównaliśmy w naszym laboratorium wydajność Pythona z często używanym językiem AWK, który również może być stosowany do przetwarzania wzorców. Próbką danych było 93k wierszy danych w formie tekstowej, a zadaniem obu skryptów było przetworzenie rekordów według określonych wzorców i wygenerowanie pliku wynikowego. Leciwy już AWK pracę wykonał w 19,6s Python zakończył zadanie po 7,04s.
Jest jeszcze jeden aspekt, który sprawia że korzystanie z Pythona jest takie atrakcyjne - to jego wszechstronność. Mnogość dodatkowych bibliotek rozszerzających możliwość użycia pytona w tak wielu różnych zastosowaniach sprawia, że nie musimy korzystać z dodatkowych narzędzi do obsługi całego procesu a to sprawia, to z kolei ogranicza złożoność procesu a mniej złożony proces to łatwiejsze i tańsze utrzymanie go w dobrej kondycji. Jak to określa Elon Musk CEO firmy SpaceX “The best part is no part”
W tym krótkim tekście wspomniałem zaledwie o kilku cechach języka programowania Python, co mam nadzieję, zaciekawi czytelników i zachęci do dalszego poszukiwania wiedzy o tym narzędziu.
Podobne wpisy

Masz pomysł? Porozmawiajmy
